7.9 KiB
Premiers modèles prédictifs
Objectif : passer de la description à la prédiction sur nos données locales, en restant simple et lisible. L’idée est de prendre le cadre posé au chapitre 8 et de le peupler avec des modèles très basiques, pour voir ce qu’ils valent réellement sur les horizons T+10, T+60, T+360 (~6 h) et T+1440 (~24 h) pour la température, le vent et la pluie, sans présupposer que “plus complexe” signifie forcément “meilleur”.
Point de départ : données, features et métriques
On travaille toujours à partir de data/weather_minutely.csv (pas 10 minutes), enrichi des variables dérivées vues au chapitre 8 : temps encodé en sin/cos, lags courts (T‑10/‑20/‑30), deltas, moyennes et cumuls glissants sur 30–60 minutes, composantes (u, v) du vent, drapeaux d’événements (pluie en cours, vent fort, chaleur/froid).
Cette table est découpée en trois blocs chronologiques : une partie train (~70 % du début de la série) pour l’apprentissage, une partie validation (~15 % suivante) pour régler les hyperparamètres, et une partie test (~15 % la plus récente) pour juger les modèles sur un futur qui n’a pas servi à l’entraînement. On peut, en variante, utiliser un time‑series split “en rouleau” comme décrit au chapitre 8, mais les figures de ce chapitre s’appuient sur une découpe simple.
Côté métriques, on reste sur les repères déjà introduits : MAE/RMSE pour température et vent, et pour la pluie binaire, le trio précision–rappel–F1 complété par le Brier score et la calibration des probabilités. Les modèles ne seront jugés intéressants que s’ils apportent un gain clair par rapport à des références naïves.
Étape 1 — Baselines de référence
python "docs/09 - Premiers modèles prédictifs/scripts/run_baselines.py"
Ce premier script ne fait qu’une chose : mesurer la performance de quelques stratégies “bêtes mais honnêtes” qui serviront ensuite de ligne de base. Il lit le dataset minuté, applique le découpage temporel, puis entraîne et évalue :
- des baselines de persistance (prédire que la prochaine valeur est identique à la dernière observée) ;
- des climatologies horaires (moyennes/quantiles par heure locale, éventuellement par saison) ;
- des moyennes mobiles à court terme ;
- un classifieur “toujours sec” pour la pluie, qui illustre à quel point la rareté des précipitations peut tromper les métriques.
Le script génère :
- deux CSV de résultats dans
docs/09 - Premiers modèles prédictifs/data/:baselines_regression.csv(température/vent, MAE/RMSE, splits validation/test)baselines_rain.csv(pluie binaire, précision/rappel/F1/Brier, splits validation/test)
- deux figures de synthèse (validation) dans
docs/09 - Premiers modèles prédictifs/figures/:baselines_mae_validation.png(MAE vs horizon pour température et vent)baselines_rain_validation.png(F1 et Brier vs horizon pour la pluie)
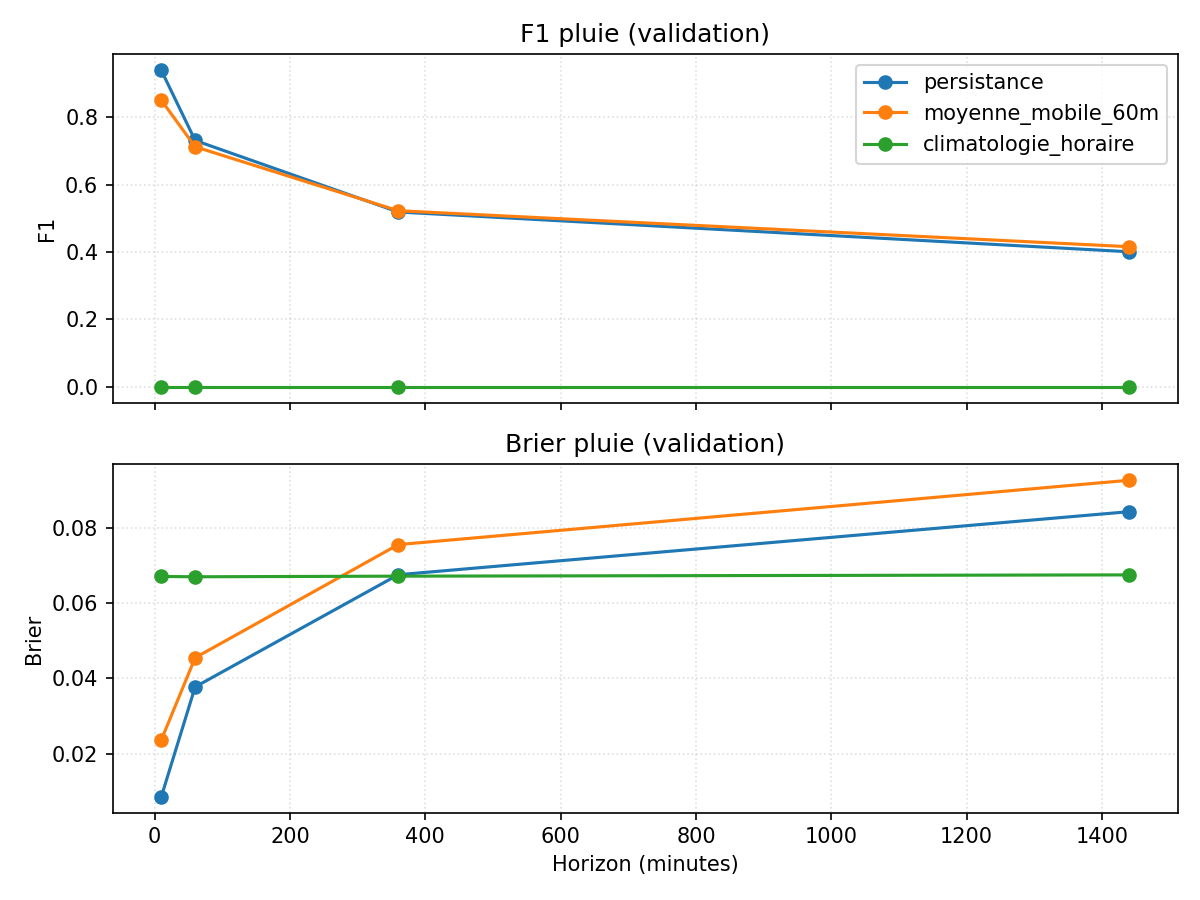
Ces deux graphiques résument ce que ces baselines savent faire, horizon par horizon.
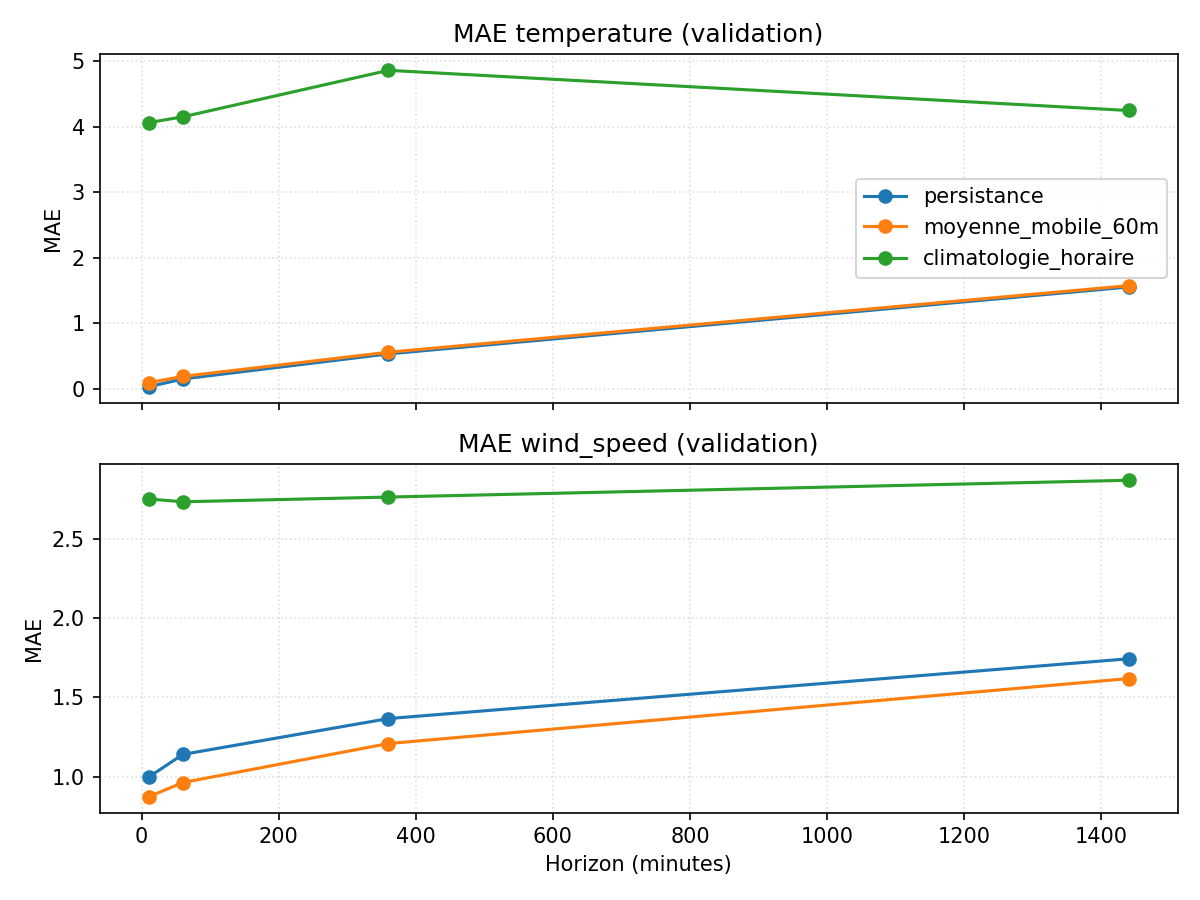
Sur la figure MAE, la persistance reste imbattable jusqu’à +6 h sur la température, avec une erreur moyenne sous le degré ; à +24 h, elle se dégrade (MAE ≈1,5 °C), mais reste nettement devant la climatologie horaire, qui plafonne autour de 4–6 °C.
Pour le vent, la moyenne mobile sur 60 minutes devance légèrement la persistance dès +10 min, mais l’écart reste modeste et la MAE grimpe doucement avec l’horizon (≈2 km/h à +24 h). Le message est clair : sur un pas de 10 minutes, les baselines “bricolées” font déjà un travail honorable, et le gain potentiel d’un modèle plus riche sera nécessairement limité.
Sur la figure pluie, la persistance profite à plein de la rareté des événements : annoncer “sec” presque tout le temps donne un F1 très élevé aux petits horizons, même si le Brier score se dégrade en s’éloignant. La climatologie horaire, sans contexte, ne voit pratiquement jamais la pluie. Toute tentative de modèle devra donc battre la persistance sur F1/Brier, surtout à +60 et +360 minutes où le score chute déjà : la barre n’est pas très haute en absolu, mais elle l’est par rapport à la quantité d’information disponible dans une simple série locale.
Ces baselines fixent donc une référence indispensable : si un modèle plus sophistiqué n’apporte pas de gain visible par rapport à elles, il ne sert à rien en pratique.
Étape 2 — Premiers modèles supervisés
python "docs/09 - Premiers modèles prédictifs/scripts/run_first_models.py"
Une fois les références en place, on passe à des modèles un peu plus élaborés. Ce second script :
- construit les variables dérivées (sin/cos temporels, lags, deltas, moyennes glissantes, vent u/v, drapeaux) à partir du CSV brut ;
- découpe en train/validation/test (70/15/15 %) ;
- utilise la matrice de corrélation décalée (chapitre 5) pour privilégier les variables/lags dont |r| ≥ 0,2, tout en conservant les cibles ; l’humidité, la pression, l’illuminance, etc. sont donc injectées quand elles sont corrélées à la cible ;
- entraîne Ridge/Lasso pour température et vent, régression logistique pour la pluie ;
- exporte
models_regression.csvetmodels_rain.csvdansdocs/09 - Premiers modèles prédictifs/data/; - produit
models_mae_validation.png(MAE vs horizon pour température et vent) dansdocs/09 - Premiers modèles prédictifs/figures/.
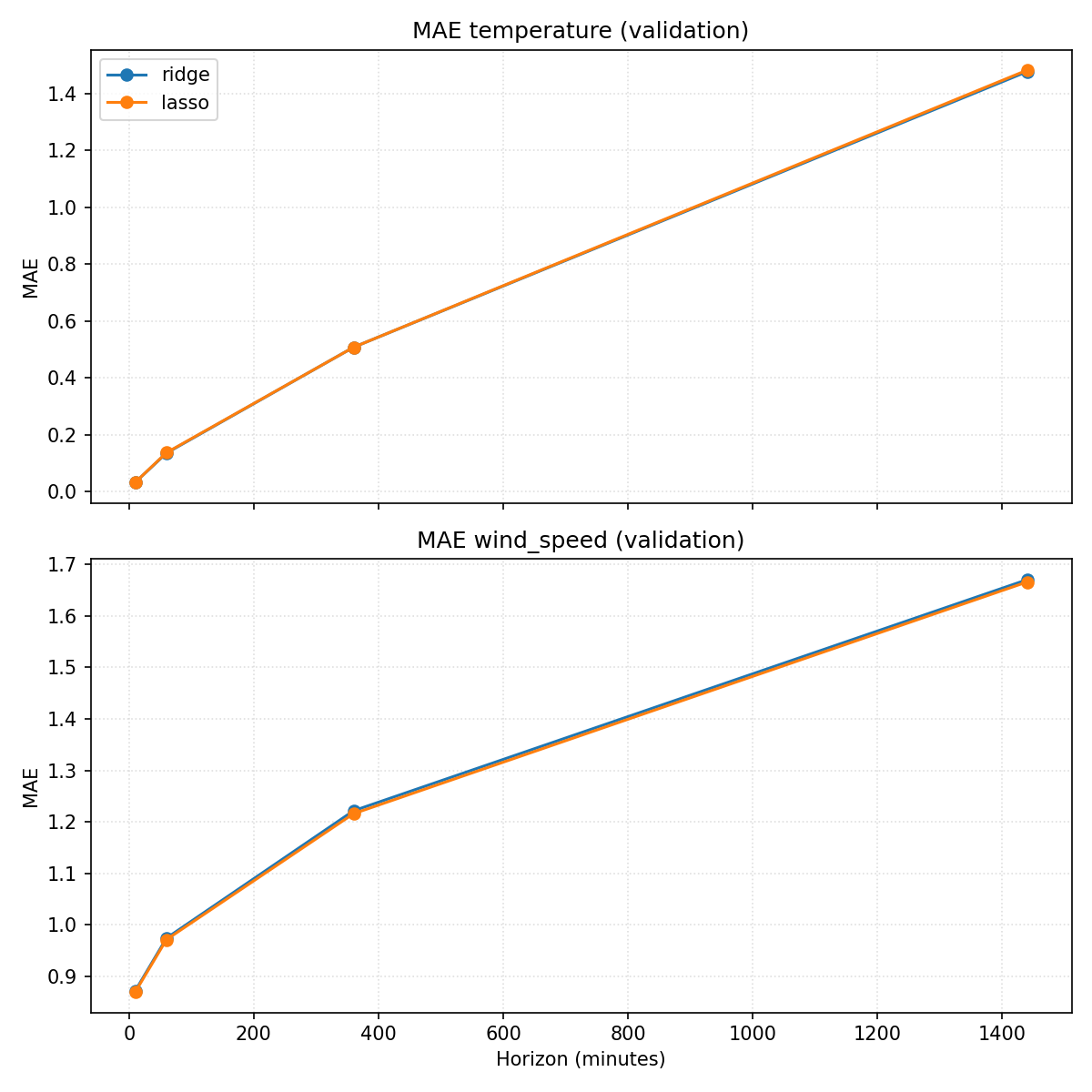
Cette figure concentre la lecture sur température et vent, en MAE vs horizon.
Côté température, Ridge/Lasso battent légèrement la persistance sur tous les horizons sauf à +10 min (MAE ≈0,14 à +60 min vs 0,15 pour la persistance ; ≈1,48 à +1440 vs 1,55). Injecter les variables corrélées (humidité, illuminance, pression…) donne un petit gain par rapport à la version “lags génériques”, mais la marge reste modeste.
Pour le vent, la logique est la même : un léger mieux que la persistance (≈0,87 à +10 min vs 0,99 ; ≈1,67 à +1440 vs 1,74), sans révolution. Les corrélations étant globalement faibles, l’apport des autres variables reste limité sur ce pas de 10 minutes.
Pour la pluie, la régression logistique ne parvient pas encore à dépasser la persistance : F1 ≈0,91 à +10 min contre 0,94 pour la persistance, puis chute rapide à +60 min et au‑delà. La probabilité produite est pourtant correctement calibrée (Brier ≈0,011 à +10 min), mais cela ne suffit pas à compenser l’avantage d’un modèle qui “reste sec” la plupart du temps. Il faudra enrichir les variables d’entrée ou changer de famille de modèles pour espérer dépasser cette baseline très difficile à battre sur une série aussi déséquilibrée.
En résumé, ces premiers modèles linéaires apportent un petit gain sur température/vent, mais échouent encore à battre la persistance pour la pluie. Ils fixent un second niveau de référence : toute complexité supplémentaire devra se justifier par un gain clair, surtout sur les horizons intermédiaires (+60/+360 min) où les baselines commencent à se dégrader.
Conclusion
Contre l’intuition, c’est au très court terme que nos modèles simples se heurtent à un mur pour la pluie : la persistance reste devant à +10 min, et l’écart se creuse déjà à +60 min.
Pour la température et le vent, les gains existent mais restent modestes, même à +10 min, alors qu’on pouvait espérer que ces prévisions soient “faciles”. Les horizons longs se dégradent comme prévu, mais le vrai défi est donc d’améliorer les prédictions proches sans sur-complexifier.
Prochaine étape : tester des modèles plus flexibles (arbres/boosting) et enrichir les features, tout en vérifiant que le gain sur les petits horizons justifie l’effort.