6.7 KiB
Conclusion
Ce que les données racontent
En partant d’une simple station météo branchée sur InfluxDB, on a fini par disposer d’un jeu de données propre, minuté, enrichi de quelques métadonnées (saison, position du soleil…). Les premiers graphiques, puis les corrélations binaires et multiples, ont montré que le signal colle plutôt bien à ce que la physique et la météorologie attendent : l’humidité qui baisse quand la température monte, la pression qui ne bouge que lentement, le vent qui se renforce dans les situations dépressionnaires, la lumière qui s’effondre sous les nuages, etc. Autrement dit, les capteurs, les scripts et les traitements ne racontent pas n’importe quoi : les grandes tendances sont cohérentes avec les mécanismes connus, dans les limites de notre période couverte (mars→novembre) et de l’absence de contexte synoptique.
Des modèles prédictifs… peu convaincants
Une fois ce socle posé, l’objectif était d’aller plus loin : construire un petit cadre prédictif local capable d’annoncer, au pas de la station, la température, le vent et la pluie à plusieurs horizons (T+10 min, +60 min, +6 h, +24 h). On a testé des baselines simples (persistance, climatologie horaire, moyennes mobiles), puis des modèles linéaires régularisés, des modèles non linéaires (arbres, forêts, gradient boosting) et enfin un modèle de type foundation comme Chronos-2, appliqué en zéro-shot sur la série de la station.
Le constat est assez net :
- les baselines « bêtes » restent très difficiles à battre sur la température et le vent à très court terme, surtout la persistance, qui fait déjà un excellent travail jusqu’à quelques heures ;
- les modèles locaux plus sophistiqués gagnent parfois quelques dixièmes de degré ou de km/h, mais rarement de quoi justifier la complexité, et ils échouent à faire mieux que la persistance pour la pluie ;
- Chronos small, même réglé prudemment, fournit un signal exploitable sur la température et un peu sur le vent pour les horizons très courts (quelques heures), mais se dégrade vite dès qu’on s’éloigne, et reste faible sur la pluie.
En résumé, ni les modèles « maison », ni Chronos ne permettent, dans cette configuration, de construire un outil de prévision local robuste, général et fiable sur tous les horizons et toutes les variables. Ils montrent des choses intéressantes, mais restent loin d’une solution utilisable au quotidien.
Retour sur l’objectif initial
L’objectif annoncé au départ était modeste, mais ambitieux : dépasser le simple plaisir de posséder une station météo pour exploiter réellement ses données, mettre en évidence des principes scientifiques, et concevoir un petit outil prédictif local. Sur les deux premiers points, le contrat est plutôt rempli : on a vérifié que les grandes relations attendues sont bien présentes, on a vu où elles se cassent faute de données manquantes (hiver absent, pas de champ de pression régional, pas de nébulosité, etc.), et on a posé un cadre d’analyse reproductible avec des scripts clairs.
Sur le volet prédictif, en revanche, l’objectif n’est pas atteint : les modèles localement entraînés restent fragiles et peu convaincants dès qu’on sort des cas « faciles », et même un modèle généraliste comme Chronos ne transforme pas magiquement la série locale en prévisions fiables pour la pluie ou les horizons plus lointains. Cela ne veut pas dire que l’exercice était inutile ; au contraire, c’était l’occasion de se confronter concrètement aux limites de ce que l’on peut faire avec une seule station et quelques mois de données.
Au passage, ça a été l’occasion de s’amuser avec Python : pipeline de préparation, génération de graphiques, scripts d’analyse, première approche de l'utilisation de l'IA avec des données concrètes et produites localement, tests de modèles… Même si rien n’est « prêt à l’emploi » pour faire tourner une mini-météo locale, le chemin a été instructif et agréable.
Ce que cela dit de la prévision météo
Travailler sur ce jeu de données rappelle une évidence que l’on oublie facilement : prévoir le temps n’est pas simple. En tant qu’humains, on a des intuitions — « ça va rester sec », « ça va se couvrir », « le vent va se lever » — qui ne sont pas forcément mauvaises, surtout quand on connaît bien son environnement. Mais dès qu’on demande à un modèle mathématique de faire la même chose, on se heurte à plusieurs réalités :
- la météo locale dépend de phénomènes qui dépassent largement ce que voit une station : dynamique synoptique, topographie, humidité en altitude, nuages, etc. ;
- plus on s’éloigne spatialement du point d’observation, plus on profite de modèles globaux qui intègrent ces informations, et donc plus les prévisions tendent à être stables à grande échelle ;
- même les meilleurs modèles opérationnels, nourris de données massives et de calcul haute performance, se trompent encore régulièrement : l’incertitude fait partie du jeu.
Dans ce contexte, rester humble est indispensable. Une simple série locale, aussi bien nettoyée soit‑elle, ne suffit pas à démontrer le « déterminisme complet » de la météo ; au contraire, elle met plutôt en lumière la part d’information manquante, et elle est colossale. Montrer que, en pratique, la météo est entièrement déterministe à l’échelle qui nous intéresse demanderait bien plus de données, de capteurs, de modèles et de temps de calcul que ce qu’on a ici.
Mot de fin
Ce projet n’aboutit pas à un modèle de prévision local prêt à l’emploi, mais il remplit une autre fonction : celle d’un carnet d’exploration. On y voit comment des données réelles, avec leurs trous et leurs biais, peuvent être préparées, visualisées, confrontées à la physique, puis poussées jusqu’à leurs limites prédictives. Si un lecteur a envie de reprendre ce travail, d’ajouter des sources externes, de tester d’autres modèles ou simplement de tracer de nouveaux graphiques, tant mieux : la station continue d’enregistrer, et l’histoire ne s’arrête pas ici.
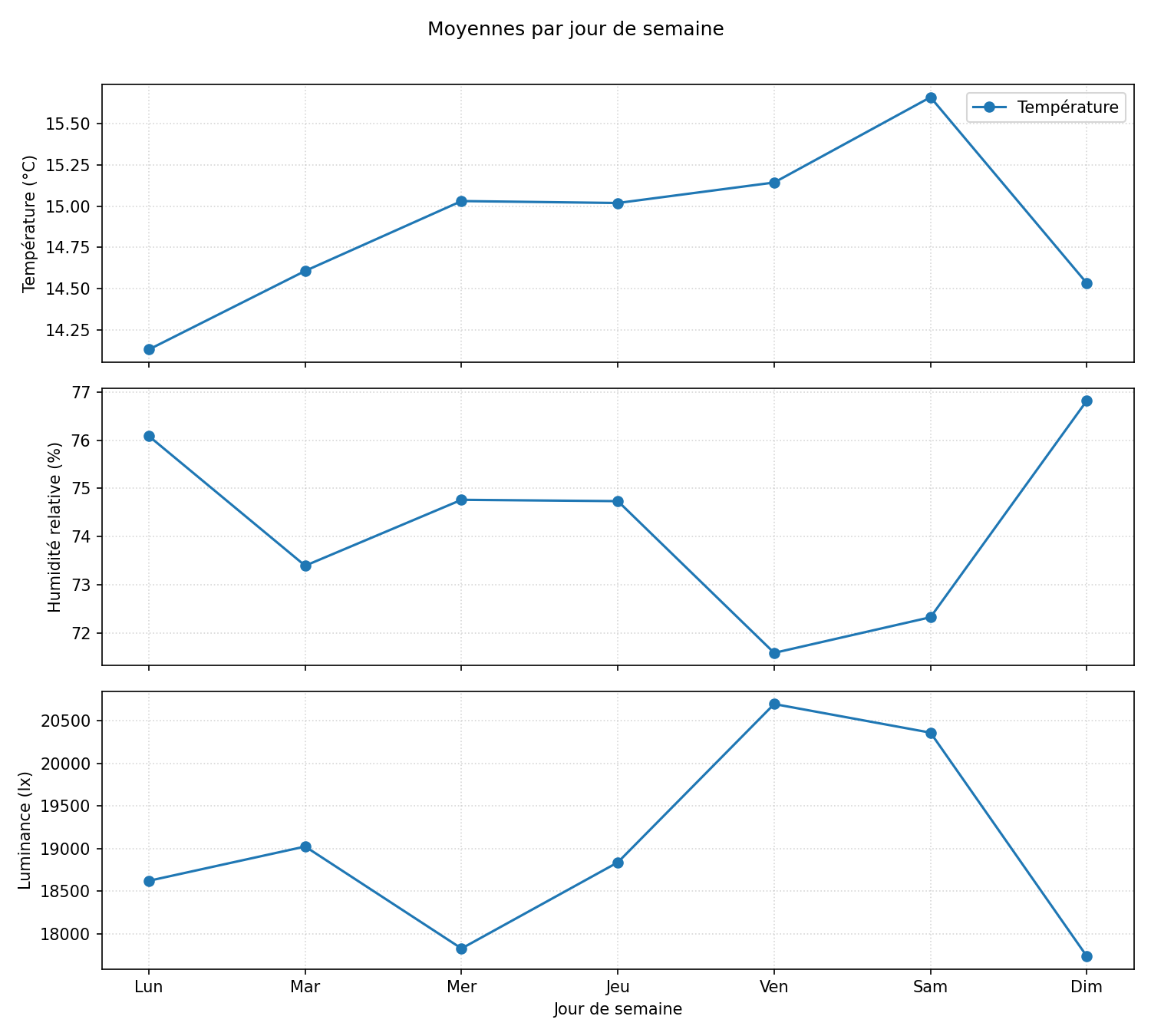
Pour finir sur une note plus légère, un petit script de curiosité :
python "docs/12 - Conclusion/scripts/plot_weekday_profiles.py"
calcule les moyennes de température, d’humidité et de luminance pour chaque jour de la semaine et produit le graphique ci‑dessous. Dans mon jeu de données, c’est le samedi qui ressort comme le jour « le plus agréable » : en moyenne un peu plus chaud, un peu plus lumineux, et moins humide que ses voisins… ce qui tombe plutôt bien pour organiser les activités du week‑end.